Entity-based SEO is a new field, full of possibilities, but where solid approaches still need to be developed. This includes the theory, the techniques and the tools for using entities to optimise your site.
For a start let’s break down confusion in understanding what SEO entities really are. Many articles have already been published on entities and their role in the evolution of web indexing. For many professionals, however, it remains difficult to understand. Why do entities make it possible to set up a sustainable SEO strategy and how they can be used to improve website performance?
This guide aims to show why you need entities to make your SEO effort more effective and how to use entities to improve on-page SEO, consolidate a site’s architecture and improve your traffic acquisition strategies.
1. What is an SEO entity?
SEO stands for Search Engine Optimization, the practice of increasing the quantity and quality of traffic to your website through organic search engine results.
From the start, SEOs have mainly focused on keywords to increase traffic.
Entity-based SEO is all about focusing on entities rather than keywords. Put it like that it’s simple, but it requires a fundamental change of mindset.
What is a keyword?
In SEO, a keyword is made up of one or more words entered by a user in a search engine such as Google or Bing.
When search engines began, the notion of keywords has formed the basis of natural referencing strategies, with the aim of ensuring the visibility of a page in search engine results, for one or more specific phrases.
Keywords have two basic characteristics:
- They carry ambiguity. A keyword can refer to several very different subjects. The keyword “Cookie” can, for example, refer to an edible biscuit or to the information sent by a Web server when a page loads.
- A keyword is most of the time specific to a language. The keyword “machine à laver” in French corresponds to “washing machine” in English or “lavadora” in Spanish.
What is an entity?
In general, an entity (or named entity to be more precise) designates a single, well-defined thing or concept which can be linked to a knowledge graph.
Unlike a keyword, which is ultimately just a collection of letters specific to a language, an entity carries meaning and is independent of the language and of the synonymous keywords that designate it.
More precisely, in the SEO world, an entity concerns any subject that can be linked to the knowledge graphs of search engines, such as the Google Knowledge Graph.
We know that Wikipedia acted as a primary trusted seed set for the Knowledge Graph. For simplicity, we can call an Entity any subject that can be attached to a Wikipedia article page, (other than disambiguation or a category pages).
For example:
Entity type | Keyword synonym | Corresponding entity |
|---|---|---|
Person | Trump | Donald Trump |
Location | Paris | Paris, France |
Organization | Alphabet | Alphabet Inc |
Event | CES |
Consumer Electronics Show
|
Concept/Thing | SEO | Search Engine Optimization |
To optimize on-page and on-site SEO, we should be focussing on which underlying entities to use to help a search engine understand the enderlying meaning of the content.
Note: there are other types of entities, such as you, your brand, your company, which while not having Wikipedia pages, can be linked to other Knowledge Graphs (such as Google MyBusiness or Linkedin). However, optimizing these entities will only improve your reputation, not your SEO.
Frequently encountered mistakes regarding entities
There are a lot of errors on the web about entities in SEO. It seems essential to us to remove any ambiguity or confusion here.
Errors encountered in SEO literature
Take, for example, this Search Engine Watch article about optimizing content using entities.
The author suggests that “player”, “best basketball shoes” and “basketball” are entities discovered by Google during the analysis of a text on basketball.
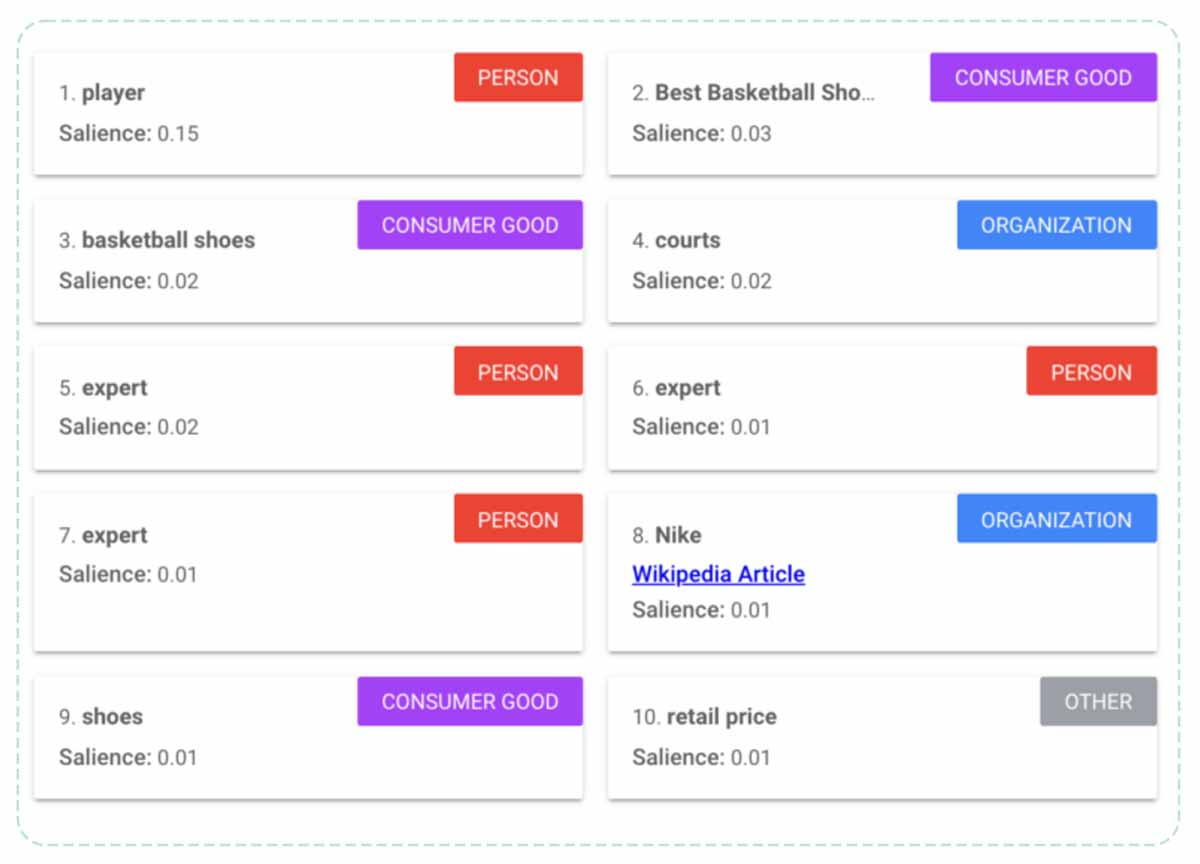
Results of the analysis of a text by the Google NLP API
What are the mistakes made here? Best Basketball Shoes certainly does not refer to an entity because there is no Wikipedia page on the subject.
Basketball shoes is also not an entity. This is a synonymous keyword referring to the Entity Sneakers.
Even the word Nike refers to the entity Nike, Inc. This entity was correctly detected by Google NLP, which creates a synonym: the word “Nike” but links to the Wikipedia page of the entity Nike, Inc.
What to remember from this:
Google only lists keywords in its natural language API interface. The entities correspond to the Wikipedia links associated with each word.
Other errors encountered
The example Wikipedia gives on its page regarding named entities is also confusing.
Here is a quote on the Wikipedia page (as of 12 Jan 2021):
…Consider the sentence Trump is the president of the United States. Both Trump and the United States are named entities since they refer to specific objects (Donald Trump and United States). However, president is not a named entity since it can be used to refer to many different objects in different worlds”
This claim is wrong for the following reasons:
- Trump is a keyword synonymous with the Donald Trump entity (and therefore the word Trump is not in itself an entity, it can also refer, depending on the context, to the Trump entity (card game) in English, or Trump in French)
- Likewise, President is a keyword synonymous with the entity President of the United States (identified in the Google Knowledge Graph by the ID / m /060d2), which can be easily disambiguated by analyzing the context of the sentence, especially since this entity is exactly named in the sentence above.
The sentence given as an example by Wikipedia ultimately referred to 3 entities: Donald Trump, President of the United States and United States.
Terminology used by Google: Entities, Topics or both?
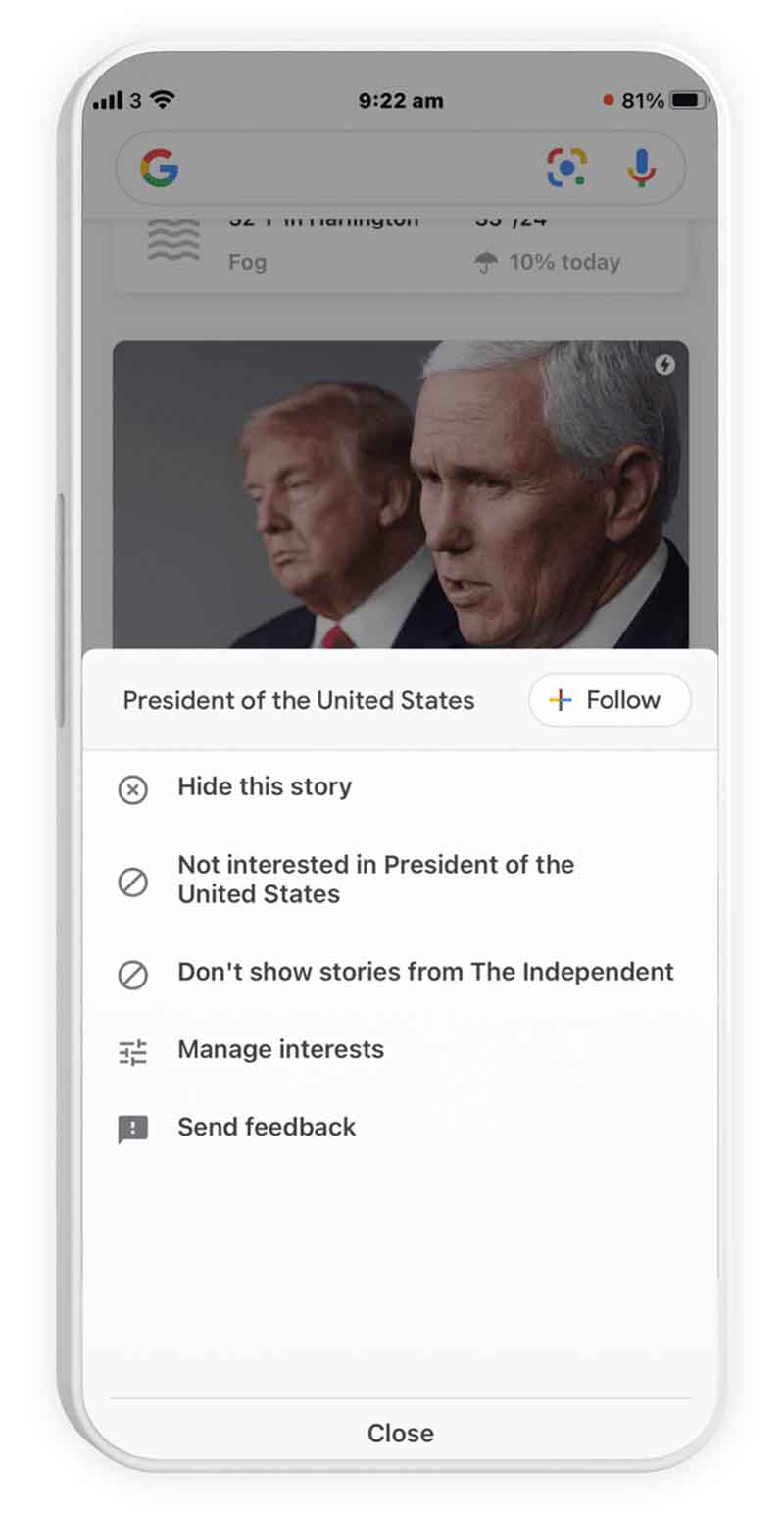
As we will see here, Google uses entities in most of its web services (Google Search, Google Discover, Google News and Google Trends in particular).
On the other hand, Google hardly ever uses the term Entity, preferring the term Subject in French or Topic in English, as shown in the screenshot left. All of the “Topics” mentioned are actually Entities.
So it’s important to be wary of the way Google names things (but you probably already know that).
2. How does Google use entities?
Why Google uses entities
Before answering the question of “How”, it is interesting to first question the “Why”. Why are entities today at the heart of Google’s algorithms and services and why are they now tending to replace keywords bit by bit?
One reason is obvious. If Google uses entities, it is because these entities make it possible to connect all the world’s information together, regardless of the language. Entities make it possible to understand the meaning of this information as well as the centres of interest of its users.
Google uses entities because these entities make it possible to connect all the world’s information together, regardless of the language. Entities make it possible to understand the meaning of this information as well as the centres of interest of its users.
By detecting the entities contained in web pages, Google will be able to link two sites talking about the same thing in different languages.
In the example opposite, Google offers, via Discover, an article in English to a French user interested in the “Search engine optimization” entity (and who has previously consulted English sites on the same topic).
We will see that personalization via entities goes far beyond Google Discover.
What Google services use entities?
In its 2018 article “ Helping you along your Search journeys ” Google already claimed to detect and index the entities contained in all web pages published on the Web, with many key applications.
If we had to summarize all of these applications, we could say that Google uses entities to interpret and categorize web pages, establish relationships between entities (and therefore between web pages), and deliver better answers to questions for Web users.
The Knowledge Graph
As reported by Google, the Knowledge Graph is used by Google Search to help users discover information faster and easier. This Knowledge Graph contains most of the real-world entities such as people, places and objects and is refreshed by a Wikipedia dump every night.
The use of the Knowledge Graph essentially allows Google to:
- Present knowledge panels for the entities searched by Internet users,
- Refine the results of its other services based on users’ interests.
Google search
The use of entities allows Google to personalize the results delivered by its search engine, based on the interests of its users and its search history.
Without second-guessing the details of updates to Google’s algorithm, many have been focussed on entities:
- Google Hummingbird: With this update, Google transformed the way it handled internet users’ queries by moving from an approach based on keywords (strings) to an approach based on entities (things).
- Google Rankbrain: RankBrain allows Google to better respond to queries that it has never encountered before. This is achieved using entities and an artificial intelligence layer.
- Google BERT: This setting uses Natural Language Processing (NLP) to understand search queries, interpret text on web pages, and thus identify entities and relationships that connect them.
Thanks to these successive improvements, Google is now able to reformulate Internet users’ requests and, it is probable, also reformulate the content of Web pages.
The search suggestions provided by Google also increasingly include entity suggestions.
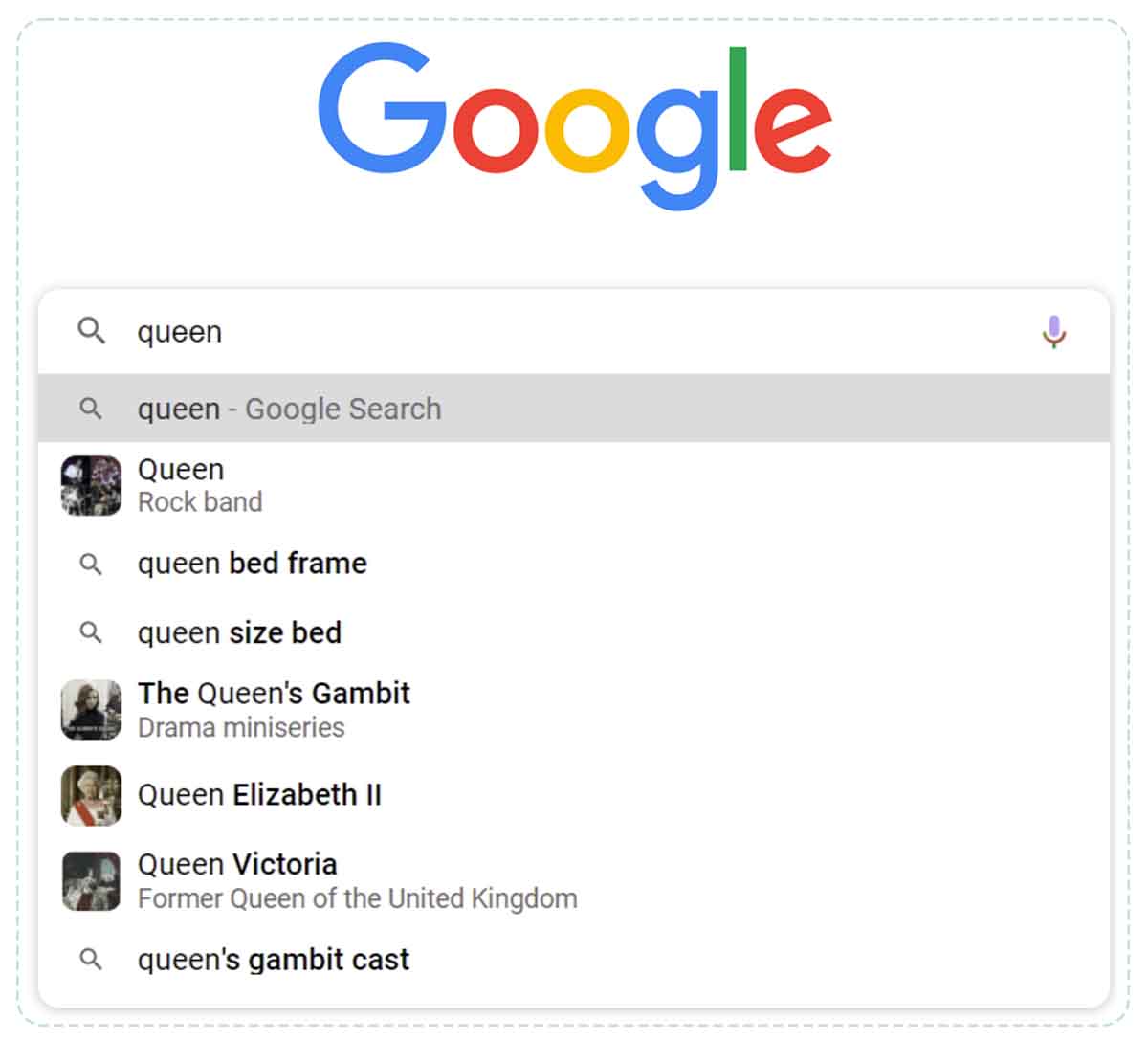
Suggestions 1,3,4 & 5 are entity suggestions.
By searching for “queen” without using the suggestion, we get a mix of ideas in the results, but using the suggestion box we can obtain a list of results which is quite surprising because it contains no errors (no suggestion of monarchs or films, for example), which clearly shows that Google delivers search results based only on entities and no longer just on keywords.
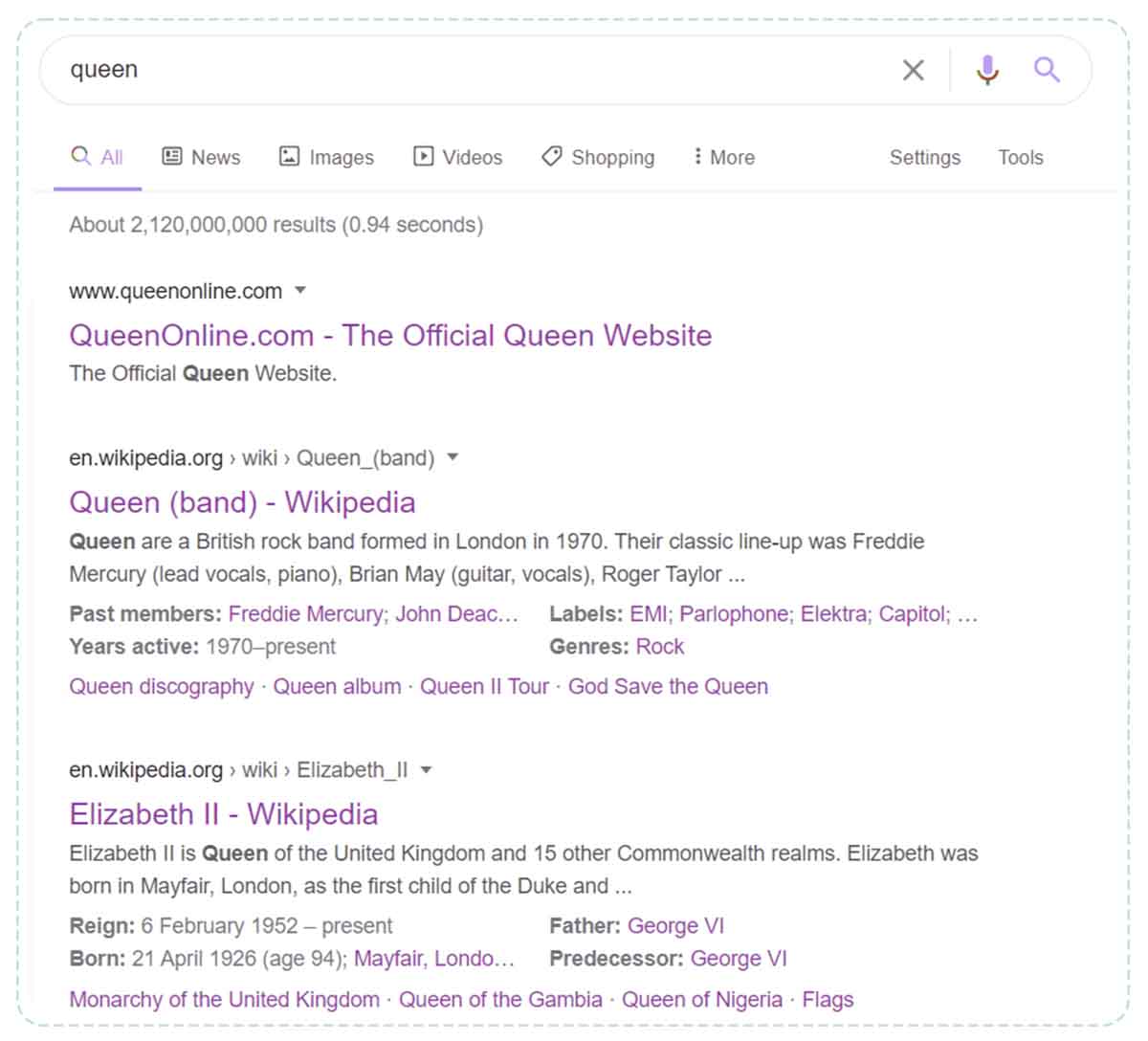
Unfiltered results for “queen”
Google Discover
As seen above, all the results offered by Google Discover are based on the interests of a user, ie the entities contained in the web pages they use. From these pages, Google builds what it calls the “ Topic Layer ” (read Entity for Topic), ie the graph of the interests of each user.
Whenever a new article is published on the web that includes one of these areas of interest, Google may suggest it to the corresponding user in Google Discover.
Google Trends
Google offers two types of research on its trends tool:
- Searching by “search term”, ie by keyword
- Search by “subject”, ie by the entity.
Here is the example of a trend for the entity /m/060d2 already seen above and accessible at the URL
https://trends.google.com/trends/explore?geo=US&q=%2Fm%2F060d2

How does Google detect entities?
The studies that we carried out with InLinks, and in particular through Industry reports, show that Google only detects on average 20% of the entities present in a text.
This result is achieved using exclusively the Google NLP API.
However, our studies show that in many cases Google’s API does not directly detect the primary entity in the articles it offers on Google Discover.
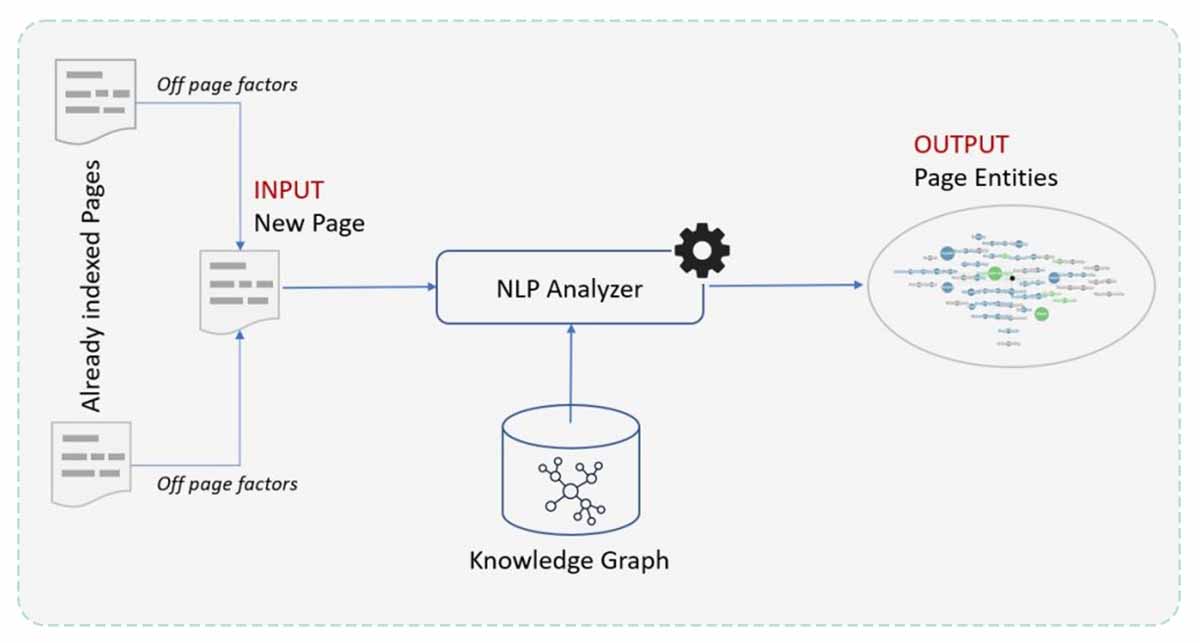
It is, therefore, reasonable to think that Google uses different methods to determine the entities present on a page:
- An NLP algorithm, similar to its API (their API detects almost 100% of people, places and organizations, but very few concepts/things),
- Off-page factors, such as the entities detected in the other pages of the site (acting as contextual entities and allowing an additional step of disambiguation)
- On-page factors such as Schema.org markup to explicitly specify the entities present in the page
Article Original Source: Inlinks